# 一、浏览器渲染
浏览器渲染过程分为了两条主线:
- 其一,HTML Parser 生成的 DOM 树
- 其二,CSS Parser 生成的 Style Rules
在这之后,DOM 树与 Style Rules 会生成一个新的对象,也就是我们常说的 Render Tree 渲染树,结合 Layout 绘制在屏幕上,从而展现出来
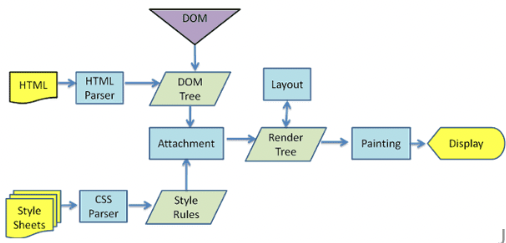
其中第二条支线就是CSS解析过程
# 二、Webkit CSS解析器
浏览器 CSS 模块负责 CSS 脚本解析,并为每个 Element 计算出样式
CSS 模块虽小,但是计算量大,设计不好往往成为浏览器性能的瓶颈
CSS 模块在实现上有几个特点:CSS 对象众多(颗粒小而多),计算频繁(为每个元素计算样式)
这些特性决定了 webkit 在实现 CSS 引擎上采取的设计,算法
Webkit 使用 Flex 和 Bison 解析生成器从 CSS 语法文件中自动生成解析器
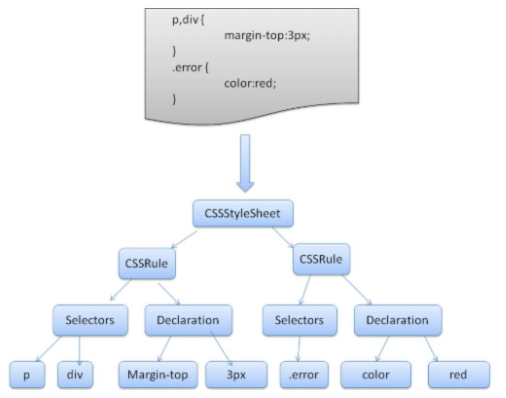
上图展示了一段简单的css代码的拆分解析过程
它们都是将每个 CSS 文件解析为样式表对象,每个对象包含 CSS 规则,CSS 规则对象包含选择器和声明对象,以及其他一些符合 CSS 语法的对象

Webkit 使用了自动代码生成工具生成了相应的代码,也就是说词法分析和语法分析这部分代码是自动生成的,而 Webkit 中实现的 CallBack 函数就是在 CSSParser 中
CSS 的一些解析功能的入口也在此处,它们会调用 lex , parse 等生成代码。相对的,生成代码中需要的 CallBack 也需要在这里实现
# 三、CSS选择器解析顺序
结论:CSS 选择器时是从右往左解析
HTML 经过解析生成 DOM Tree;而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图
Render Tree 中的元素与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的行会成为 render tree 种不同的 renderer
也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素
建立Render Tree 时,浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果来确定生成怎样的 renderer
对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并
选择器的解析实际是在这里执行的:在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector
如果正向解析,例如div div p em,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低
总结来说:样式系统如果从左往右读取css规则,那么大多是规则读到最后才会发现是不匹配的,这样做会费时耗能,如果采取从右往左的方式,那么只要发现最右边的选择器不匹配就可以直接抛弃